StoatFlow: Kafka Streams compatible engine built to scale up — not out
TL;DR
- What: Single-replica JVM stream processor with the Kafka Streams DSL — JDK 25, Project Loom virtual threads.
- Kafka Streams DSL compatibility: Drop-in — existing topology code ports with a dependency swap.
- Why: up to 3.4× less CPU and 7.8× less container memory than Kafka Streams on the same hardware; up to 13.6× lower P99 latency on stateful workloads.
- The catch: one instance per app, so no horizontal scale-out. A single 8-vCPU machine saturates around 200–300 MB/s of uncompressed throughput — well above most stream-processing workloads, but a real ceiling.
- Access: Private alpha — reach out for early access.
Most stream-processing workloads fit on a single machine. Kafka Streams and Flink scale them out anyway — and you pay the architectural cost of distribution whether your workload needs it or not.
StoatFlow is the alternative for the workloads that don't. Same Kafka Streams DSL, one replica per app, built on JDK 25 virtual threads: your existing topology code compiles against StoatFlow, and your operators stop paying the distribution tax.
For the how, head to Getting Started.
What we set out to fix
Stream processing on the JVM gives you two well-known choices: Kafka Streams or Apache Flink. Both are remarkable. Both also scale horizontally by default — which is where most of their architectural and operational complexity comes from.
Three problems compound:
- Hard to build, harder to run. Stateful joins, exactly-once, watermarks on out-of-order streams — each is a deep practice. Production then layers on rebalance storms, restart loops, checkpoint failures, and state migrations that miss SLAs.
- Every layer is a decision. Which Kafka client knobs to tune? What about RocksDB? StatefulSets, persistent volumes, static group membership, standby replicas? Deploy on Kubernetes without downtime? You answer all of it before your first event flows.
- Most workloads don't need to scale out. A workload that comfortably fits on one modern machine pays the distribution tax for capacity it will never use.
A different approach
StoatFlow runs as exactly one instance per application. No consumer-group rebalancing — there's no group. No state migration — state lives on the instance that owns it. No repartition topics — key-changing operations route through in-memory queues to other lanes inside the same process.
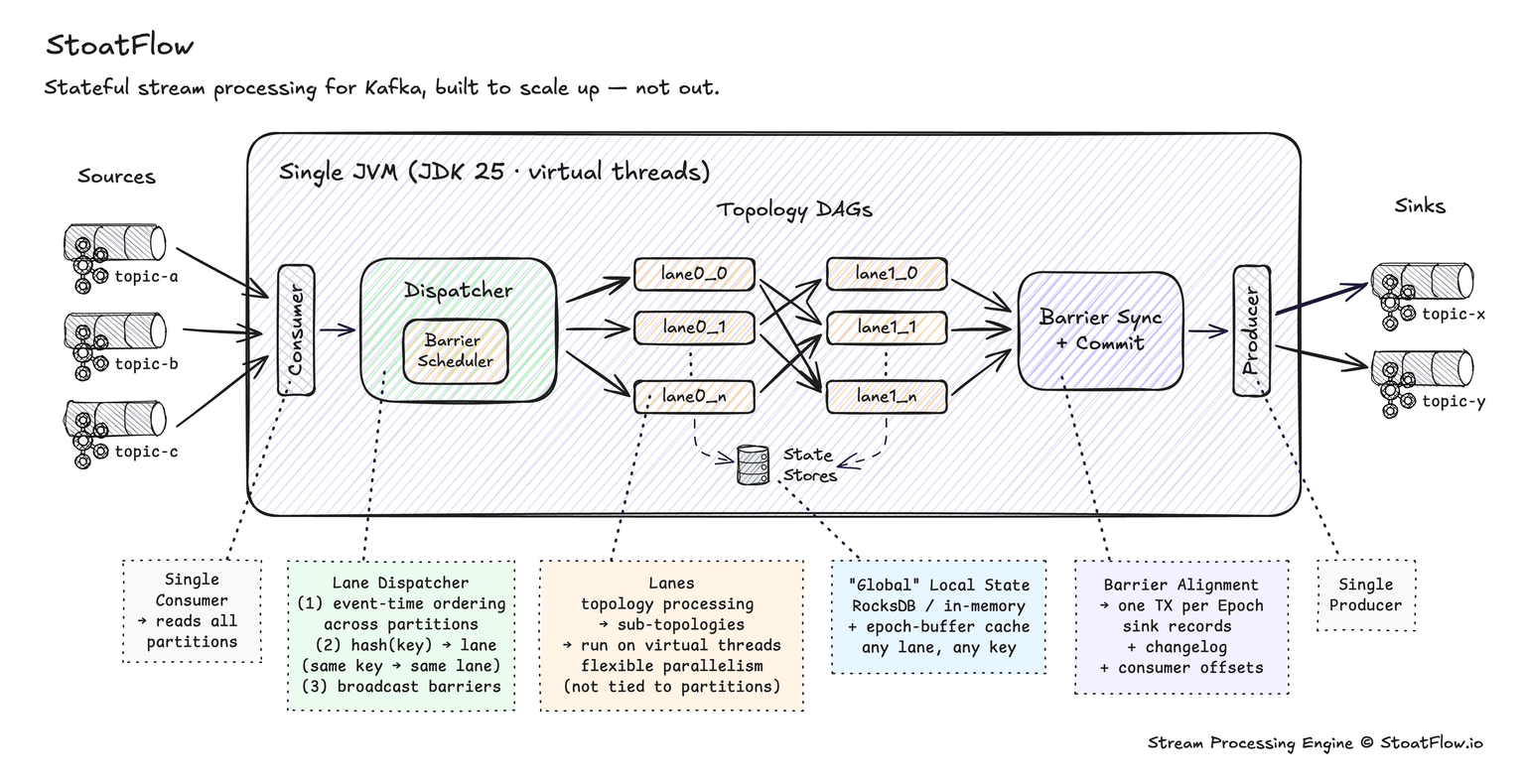
The single-replica bet rests on two recent shifts:
- Modern JVM concurrency. Virtual threads (GA in JDK 21) give you thousands of concurrent lanes without platform-thread overhead. StoatFlow targets JDK 25 — virtual threads, structured concurrency, and the Foreign Function & Memory API all in.
- Modern hardware. 16-vCPU compute-optimised instances, 10+ Gbps networking, NVMe storage — off-the-shelf on every major cloud.
From there, the model is a few moving parts that fit together:
- Records dispatch to key-affinity lanes by consistent hashing — same key, same lane, ordered. Lane count is decoupled from Kafka partition count, so parallelism scales with cores, not partitions.
- Key-changing operations stay in-process — they route to another lane through an in-memory queue, with no repartition-topic round-trip through the broker.
- State (RocksDB or in-memory) is globally accessible to any virtual thread, by any key — layered with epoch buffers for read-your-writes consistency.
- Exactly-once flows through commit barriers that sweep every lane and align with a single Kafka transaction.
Your topologies port unchanged
The DSL is the one Kafka Streams users already know: KStream, KTable, joins (primary-key, foreign-key, windowed), count / reduce / aggregate / cogroup, tumbling / hopping / session windows with grace and suppression, versioned state stores, the Processor API, and interactive queries — all there.
Existing topologies port with a dependency swap and a config cleanup. Your StreamsBuilder, your operations, your Materialized definitions all compile against StoatFlow. What you delete is the multi-instance scaffolding: standby replicas, stream-thread counts, partition-aware tuning.
And on top of the DSL, StoatFlow ships primitives Kafka Streams doesn't:
- Flink-style event-time and processing-time timers from any
Processor - Flink-style watermarks with idleness alignment
- Scheduled sources — topology-level emitters on an interval or cron
- Atomic store operations (
compute,merge) - KeyLockManager — atomic sections across multiple keys and stores
For the full surface, see Features.
The numbers
Benchmarked against Kafka Streams 4.1.1 on a Hetzner 8-vCPU machine — identical topologies, throughput parity:
- P99 latency — up to 13.6× lower
- CPU — up to 3.4× less
- Container memory — up to 7.8× less
- State restoration — 1.45 to 1.65× faster
The full benchmark report walks every scenario — topology, infrastructure stack, serdes (String / Avro / Protobuf), load rates, and event-size distributions — so you can compare against the workloads you actually run.
Where StoatFlow fits — and where it doesn't
One instance per app is a deliberate trade, and it has edges worth stating plainly.
- There's a single-machine ceiling, and we name it. On that Hetzner 8-core VM, benchmarks measure a 200–300 MB/s uncompressed network-bandwidth ceiling — roughly ~124K events/sec on a 1KB stateless transform, up to ~2.1M events/sec output on word-count-style aggregation. High-end hardware (96+ cores, faster NICs) hasn't been benchmarked yet.
- No horizontal scale-out — by design. If a workload genuinely needs to span machines, that's not a StoatFlow workload; Kafka Streams and Flink remain the right answer.
- State migration is a reprocess, not a restore. The recommended path onto StoatFlow is to reprocess your input topics — direct restoration from existing Kafka Streams changelog topics isn't supported. If your input retention rules that out, get in touch.
- This post doesn't cover everything. Failover behaviour, cold-start times, and how representative the benchmark scenarios are for your workload are all fair questions — and the docs are still being written.
All of this is where the 1.0.0 alpha stands today, not where it's headed. The single-replica design is deliberate and here to stay — but how far one replica goes is exactly what we keep pushing. Benchmarking higher-end hardware to lift the throughput ceiling, shortening cold starts, widening the scenarios we measure, and ongoing refactoring and tuning for more performance on the same hardware are all in flight; the numbers above are a starting point, not a finish line. Scaling up harder is the point — expect these edges to move.
Get early access
StoatFlow is in private alpha — distribution is invite-only while we work directly with each early-access team.
Reach out to request alpha or beta access — especially if you're running stateful Kafka Streams in production today. For release news and updates, follow on LinkedIn.